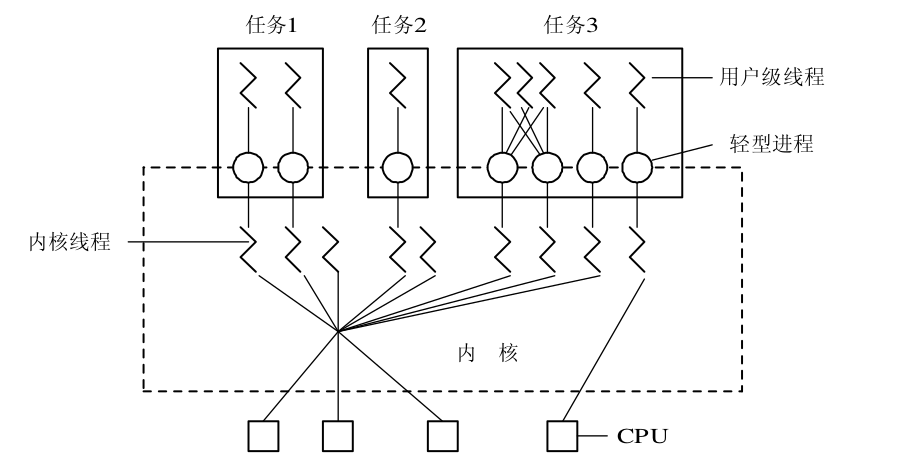
工作区和暂存区
git设计中有一些概念,了解这些概念对于深入学习git有很大的帮助。其中就有工作区
和暂存区。
工作区
工作区就是创建的工作目录,这个目录下的所有文件都需要在git的管理之下。文件的创
建,修改,删除都会被git记录。
暂存区
另外一个就是.git。这个称为版本库。版本库里存了很多东西,其中一个就是暂存区,所
有的修改只有在提交到暂存区,才能被commit。1
2
3
4
5
6
7
8
9
10位于分支 master
要提交的变更:
(使用 "git reset HEAD <文件>..." 以取消暂存)
修改: readme.txt
未跟踪的文件:
(使用 "git add <文件>..." 以包含要提交的内容)
LICENSE
git add 是将文件修改添加到暂存区
git commit 是将暂存区的所有内存提交到当前分支上
管理修改
上一节提到暂存区和工作区,git管理的是修改,而不是文件文件。为什么这样说呢,实验
一下。
原readme.txt中的内容:
1
2git is a version control tool
git is so nice
第一次修改后的内容:
1
2
3git is a version control tool
git is so nice
this is first test
使用命令:
1
2
3
4
5
6
7
8
9
10
11
12xxx:~/workplace/demo$ git add readme.txt
xxx:~/workplace/demo$ sudo git commit -m "first"
[master e76954f] first
1 file changed, 3 insertions(+)
create mode 100644 readme.txt
xxx:~/workplace/demo$ git status
位于分支 master
无文件要提交,干净的工作区
xxx:~/workplace/demo$ cat readme.txt
git is a version control tool
git is so nice
this is first test
第二次修改的内容:
1
2
3
4git is a version control tool
git is so nice
this is first test
this is second test
使用一下命令:
1
2
3
4
5
6
7
8
9 xxx:~/workplace/demo$ sudo git commit -m "test"
位于分支 master
尚未暂存以备提交的变更:
(使用 "git add <文件>..." 更新要提交的内容)
(使用 "git checkout -- <文件>..." 丢弃工作区的改动)
修改: readme.txt
修改尚未加入提交(使用 "git add" 和/或 "git commit -a")
由上面执行结果可以,第二次的修改并未被提交。
这也说明,只有将修改添加到暂存区才能进行后一步的提交。也能看出来git的确
是对修改进行管理的,只有当修改添加到暂存区,才能把修改提交到分支上。文件已经
被修改了,但是并不会被提交。
撤销修改
上一次讲过git的时光魔法,利用git reset可以让文件回到某一状态。但是针对的
是提交后的。每次reset的标记也是commit id。
还有一种状况需要考虑,就是在修改没有commit之前,如何让文件恢复到某一时刻的
状态。
git checkout就是专门负责则这个功能的。
1
2
3
4
5
6
7
8
9
10
11xxx:~/workplace/demo$ cat readme.txt
git is a version control tool
git is so nice
this is first test
this is second test
this is modify.
xxx:~/workplace/demo$ git checkout readme.txt
xxx:~/workplace/demo$ cat readme.txt
git is a version control tool
git is so nice
this is first test
可以从上面的命令清楚的看到,git checkout命令就相当于撤回键一样,可以让修
该回到之前的一个状态。
还有一个需要考虑的是,如果你的修改已经被提交,那么需要使用reset来回到上一个
状态。
删除修改
1 | xxx:~/workplace/demo$ rm readme.txt |